Seamos sinceros: escalar una plataforma de IA conversacional no se parece en nada a escalar una web. En Konect, nuestra pasarela de IA conversacional, procesamos conversaciones a escala real. Transcribimos audio, lo analizamos con LLMs y lo indexamos para búsqueda híbrida. Y cada una de esas tres cosas se comporta de una forma completamente distinta cuando llega la carga.
Es, por naturaleza, un trabajo “incómodo”: irregular, heterogéneo y con picos que no avisan. Justo por eso resulta un banco de pruebas honesto para hablar de escalabilidad de verdad, la que se nota en la factura de infraestructura y en la latencia que percibe cada usuario. En esta entrega del Rincón Friki abrimos el capó y te contamos cómo lo resolvemos, con una arquitectura de workers asíncronos sobre Kubernetes y, sobre todo, gobernada con GitOps con ArgoCD, que nos permite escalar cada cuello de botella por separado sin tocar el resto del sistema.
Tres tareas, tres mundos distintos
Antes de escalar nada, conviene mirar de cerca qué estamos escalando. Konect combina dos pipelines principales detrás de una API REST construida con FastAPI: la transcripción de audio (con su análisis posterior mediante LLM) y el análisis de email. La API es deliberadamente delgada y hace lo justo: valida la entrada, autentica contra Keycloak, persiste el job en PostgreSQL y encola la primera tarea. A partir de ahí, toda la lógica pesada vive en workers asíncronos que consumen tareas desde una cola Redis. Cada job es una secuencia de steps declarados en un campo recipe. Y aquí está el quid de la cuestión: esos steps no se parecen en nada entre sí.
- Transcripción (STT). Intensiva en CPU (o GPU), con tareas largas y ficheros de audio de hasta 500 MB que hay que descargar de MinIO y procesar.
- Análisis con LLM. Limitada por entrada y salida, y por los rate limits del proveedor. Pasa la mayor parte del tiempo esperando respuestas de la API del modelo.
- Indexación. Ligera y rápida: genera embeddings y consolida el documento en Typesense para búsqueda híbrida.
Ponlo todo junto y verás el problema. Si metiéramos los tres steps en el mismo proceso y escaláramos «el worker» como un bloque monolítico, cada pico nos saldría carísimo: para absorber una avalancha de transcripciones tendríamos que replicar también el análisis y la indexación, que no lo necesitan. Y al revés. La conclusión es clara: para escalar con cabeza hay que poder escalar cada tipo de tarea por separado.
¿Cómo le decimos a cada worker qué le toca?
La respuesta de Konect es «sencilla». El worker (main_worker) es un único proceso Taskiq que ejecuta los pasos en orden, pero no todas las réplicas tienen que hacerlo todo. Una variable de entorno, WORKER_TASKS, decide qué tipos de tarea acepta cada réplica:
transcriptionanalysisemailemail_analysisindexing
Por debajo, el broker se apoya en Redis Streams, con un stream por nombre de tarea (jobs.process_transcription, jobs.process_analysis, jobs.process_indexing, etc.). La API publica con AsyncKicker a través de un TaskiqPublisher, y cada grupo de workers consume solo su stream.
¿La consecuencia? Pura elegancia operativa. Si la transcripción es el cuello de botella, levantamos más réplicas con WORKER_TASKS=transcription y dejamos en paz a los demás. Cada subsistema escala a su propio ritmo, marcado por la profundidad de su cola y no por la del vecino.
Una imagen, muchos roles (gracias, Kubernetes)
En producción, cada servicio de Konect es un Deployment independiente bajo k8s/base/. Y hay un detalle que nos gusta especialmente: la API y el worker comparten la misma imagen Docker, y solo cambia el comando de arranque.
- API:
uvicorn server.app.main:app - Worker:
taskiq worker workers.main_worker.app.broker:broker
Separar workers por tipo de tarea es, entonces, tan sencillo como desplegar varias réplicas de nixon-worker con distinto WORKER_TASKS. Cada entorno ajusta su configuración con overlays de Kustomize (por ejemplo, reta-demo u omnia-demo) y existe un chart Helm equivalente en helm/konect-nixon/. Antes de seguir, este es el mapa completo de lo que estamos montando:
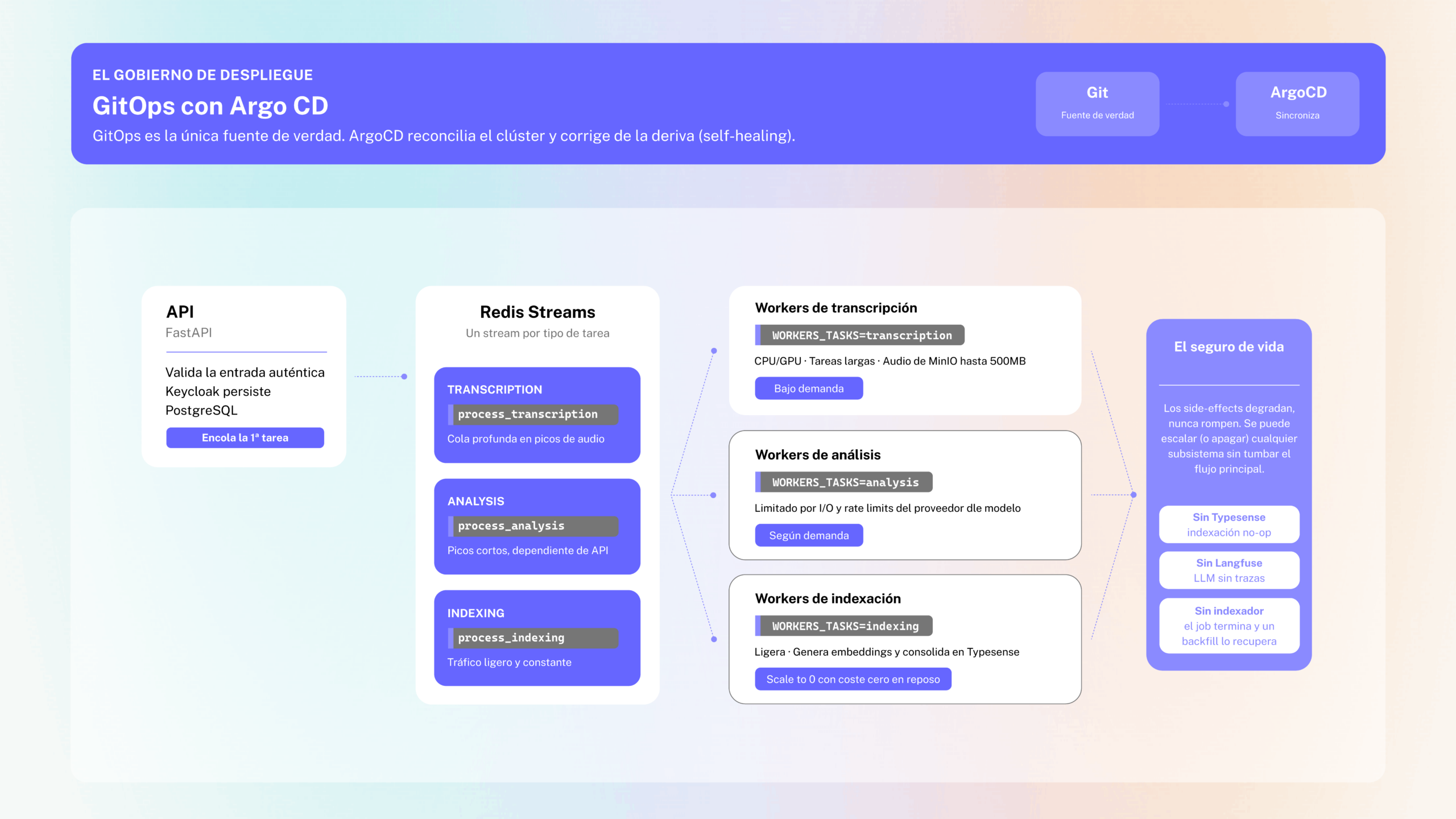
Autoescalar por lo que importa: la cola, no la CPU
Como el trabajo es dirigido por cola, el mecanismo natural no es escalar por CPU, sino por profundidad de cola: cuántos mensajes pendientes hay en cada stream de Redis. Con un autoescalador orientado a eventos como KEDA, sobre el HorizontalPodAutoscaler de Kubernetes, cada grupo de workers puede hacer dos cosas complementarias.
Bajar a cero cuando no hay nada que hacer
Los workers de análisis de email pueden pasar horas sin tráfico. Cuando su stream está vacío, las réplicas bajan a cero y dejan de consumir recursos. Cero trabajo, cero coste. Y sí, eso se nota en la factura.
Crecer a N cuando llega la avalancha
Cuando entra un lote masivo de audios, el stream de transcripción se llena, KEDA detecta el lag y aprovisiona tantas réplicas como hagan falta para vaciarlo en paralelo. La latencia que percibe cada usuario se mantiene baja. Y cuando el pico pasa, todo vuelve a contraerse solo.
El cerebro de todo esto: GitOps con ArgoCD
Hasta aquí tenemos un gran mecanismo para escalar. Pero un mecanismo no basta: hace falta que alguien lo gobierne. Aquí entra ArgoCD, y es lo que, en nuestra opinión, separa «escalar» de «escalar de forma fiable y reproducible».
Toda la topología de escalado de Konect (cuántos tipos de worker hay, qué WORKER_TASKS lleva cada uno, sus requests y limits de recursos, sus umbrales de autoescalado y sus overlays por entorno) es estado declarativo. Vive en manifiestos de Kubernetes versionados en Git. ArgoCD toma ese estado deseado como única fuente de verdad y reconcilia el clúster sin descanso para que coincida con él. ¿Por qué esto garantiza la escalabilidad y no solo la facilita? Por tres razones muy concretas:
- Escalar es código revisable. Pasar de tres a seis réplicas de transcripción, o cambiar un umbral de autoescalado, no es un comando manual lanzado a las 3 de la madrugada: es un pull request. Queda revisado, auditado y trazable.
- Se cura solo (self-healing). Si alguien toca un
Deploymenta mano, o un nodo cae y el clúster se desvía de lo declarado en Git, ArgoCD detecta la deriva y la corrige. La capacidad de escalado que prometimos en Git es la que el clúster mantiene de verdad. - Cada entorno, su medida. Los overlays de Kustomize (
reta-demo,omnia-demoy demás) permiten que cada entorno tenga su propio dimensionado, más análisis en uno y más transcripción en otro, partiendo de la misma base. ArgoCD despliega cada overlay en su sitio y los mantiene sincronizados.
En resumen: Taskiq, Redis Streams y WORKER_TASKS nos dan el mecanismo para escalar cada cuello de botella por separado, y ArgoCD nos da el gobierno para que ese escalado sea declarativo, reproducible y autocurativo en cada entorno.
El seguro de vida: degradar sin romper
Queda un último principio, y es el que hace que toda esta gimnasia sea segura. Konect impone una invariante en cada subsistema: cualquier side-effect fuera del happy path se degrada en silencio cuando falta. El pipeline de jobs es la única promesa del sistema al cliente; todo lo demás es un extra.
- Si Typesense no está disponible, la indexación es un no-op: el job se procesa, queda en PostgreSQL y, simplemente, no aparece en búsqueda. Sin caídas.
- Si falta Langfuse, el LLM se ejecuta igual, solo que sin trazas de observabilidad.
- Si el servicio de indexación no está, el job termina igualmente como
COMPLETEDy un backfill lo recupera más tarde.
Para una arquitectura que escala piezas de forma independiente, esto es oro. Significa que podemos escalar (o apagar) un conjunto de workers sin miedo a que su ausencia momentánea rompa el flujo principal. Degradación elegante y escalado independiente son, en el fondo, dos caras de la misma moneda: resiliencia.
Lo que nos llevamos
La escalabilidad de Konect no es un truco mágico. Es la suma de tres decisiones que se sostienen entre sí:
- Desacoplar por tipo de tarea con
WORKER_TASKS, para que cada cuello de botella escale a su ritmo. - Autoescalar por eventos sobre Kubernetes, bajando a cero sin carga y subiendo a N cuando llega el pico.
- Gobernar con GitOps con ArgoCD, para que toda esa topología sea declarativa, revisable y autocurativa en cada entorno.
Y debajo de todo, la filosofía de que los efectos secundarios degradan pero nunca rompen, que convierte cada operación de escalado en una maniobra segura. El resultado es una plataforma que crece y se contrae sola, que cuesta lo justo cuando está ociosa y rinde cuando hace falta, sin que nadie tenga que tocar un kubectl a mano de madrugada.

{kind=link}
{kind=link}
{kind=link}