
Un cliente dicta su DNI por teléfono. Lo hace como lo hacemos todos: cifra a cifra, con alguna pausa, a veces repitiendo un número cuando duda. Medio segundo después, el sistema ha validado la letra, ha comprobado el formato y ha continuado con la conversación. No ha pasado por la nube. No ha facturado ni un token. No ha salido del rack del cliente.
Esto es lo que queríamos contar hoy. Cómo lo hacemos, con qué piezas y por qué decidimos que el camino correcto era construir un pipeline de NLP híbrido en local en lugar de tirar de la API de moda. Si ya leíste nuestro artículo sobre por qué no todo debe resolverlo un LLM, este es el capítulo técnico que va a continuación. Ahí defendimos el enfoque. Aquí te enseñamos el motor.
El texto oral no se parece a nada
Conviene empezar por el problema, porque se entiende mal. La gente imagina que procesar lenguaje natural en un IVR es como procesar un formulario web con texto libre, pero no lo es. Lo que entra en el sistema es una transcripción de voz en tiempo real: la materialización textual de alguien hablando por teléfono, con su ritmo, sus dudas, su ruido de fondo y sus formas de decir las cosas. Una dirección dictada no viene como "Gran Vía 42"; viene como "gran vía cuarenta y dos", o como "la gran vía, el número cuarenta y dos", o como "gran vía... gran vía cuarenta y dos, sí".
Queda claro que el modelo de lengua que funciona aquí no es el mismo que funciona con texto escrito. Y, sobre todo, el coste de equivocarse es diferente: si el sistema mete un 6 donde había un 8 en un IBAN, el problema no es estético.
Durante los últimos años la narrativa dominante ha sido «échale un LLM y listo». Y funciona, a veces. Pero introduce cuatro problemas de los que los equipos de producto se dan cuenta tarde: latencia, coste por token, dependencia de un proveedor externo y — este es el gordo — datos personales saliendo de la infraestructura del cliente. Si trabajas con sanidad, banca o administración pública, el último problema no se negocia.
La idea de fondo: usar la herramienta adecuada para cada problema
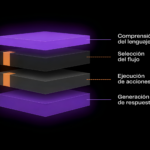
La arquitectura que usamos parte de una observación sencilla de ingeniería. Las técnicas de procesamiento de lenguaje no son equivalentes entre sí: cada una está diseñada para un tipo de problema distinto, y cada una tiene un coste computacional y una latencia muy diferentes. Aplicar a todo la técnica más potente es como usar un martillo neumático para colgar un cuadro: funciona, pero no es ingeniería, es fuerza bruta. Lo que proponemos es lo contrario. Un diseño por capas en el que cada problema se resuelve con la técnica proporcionada a su complejidad real.
Tratar cada uno con la herramienta que le corresponde no es un ahorro, es rigor. Y como consecuencia sale un sistema rápido, sostenible y auditable, porque cada capa hace algo específico, contrastable y trazable. Nuestro pipeline de NLP híbrido en local aplica este principio en tres niveles que se encadenan según la confianza del resultado. Si la capa anterior resuelve con certeza, la conversación avanza. Si no, el problema escala hacia técnicas con más capacidad de interpretación.
Capa 1 — Lo que se puede hacer con un if, hazlo con un if
Hay datos que no son ambiguos: un teléfono es un teléfono, un DNI es un DNI, un importe es un importe. Tienen reglas, tienen validadores, tienen formatos normalizados. Para esto no hace falta un modelo: hace falta un handler bien escrito.
El handler de DNI convierte «uno dos tres cuatro cinco seis siete ocho zeta» en 12345678Z y, de paso, comprueba la letra de control. El handler de teléfono reconoce «seis uno cinco…» y devuelve +34615.... El handler de IBAN valida el checksum. El handler de fecha interpreta «el dos de mayo» y «el dos del cinco» como la misma cosa.
Suena trivial escrito así, pero no lo es. Lo que hace que esta capa funcione en producción es:
- Un catálogo amplio de handlers que cubre las variables que aparecen en las conversaciones.
- Validación de integridad en cada uno de ellos: un handler que no valida acepta basura.
- Una interfaz homogénea que permita añadir nuevos tipos sin tocar lo existente.
Capa 2 — Cuando la ortografía del que transcribe no coincide con la nuestra
Un paciente dice «quiero pedir cita con el otorrino». En tu catálogo de especialidades médicas pone «Otorrinolaringología». No hay coincidencia exacta, pero cualquiera con dos ojos ve que «otorrino» es lo mismo.
Esto es un problema clásico de similitud léxica y se resuelve sin LLM. rapidfuzz lleva años haciéndolo muy bien: partial_ratio y WRatio comparan cadenas y devuelven una puntuación. Con un umbral razonable (por ejemplo, 75 sobre 100) y un diccionario bien construido de intenciones y sinónimos, se cubre la enorme mayoría de la clasificación de intents en cuestión de microsegundos.
Esta capa funciona tan rápido y con tanta fiabilidad que no tiene sentido sustituirla por algo más sofisticado mientras siga cubriendo el caso. El principio de diseño se cumple aquí con naturalidad: cuando un problema es léxico, la solución correcta es léxica. Trabajos recientes en arquitecturas híbridas de LLM publicados en ICLR 2024 apuntan en la misma dirección: combinar módulos deterministas y semánticos ganando a los modelos monolíticos con el mismo presupuesto. No lo decimos solo nosotros; lo dice la literatura.
Capa 3 — El LLM donde el problema sí es de comprensión
Y sin embargo, hay casos que ni las reglas ni la similitud léxica resuelven. Alguien describe un síntoma con sus propias palabras y toca mapearlo a una especialidad médica. Alguien explica una incidencia técnica con un vocabulario que no encaja con ninguna taxonomía preexistente. Ahí es donde el LLM sí aporta valor — cuando hace falta razonar sobre el significado.
Nuestra decisión aquí va a contracorriente de lo que hace la mayoría: no usamos modelos de 70.000 millones de parámetros. Ejecutamos Qwen 2.5 de 1.500 millones, cuantizado en formato Q4_K_M, servido con Ollama. El modelo entero ocupa menos de 2 GB en disco. Se ejecuta en CPU pura sobre un servidor empresarial estándar con AVX2. Sin GPU. Sin llamadas externas.
Una clasificación semántica compleja tarda entre 3 y 4 segundos en responder. Es más de lo que tarda una API en la nube, sí. Pero como a este modelo solo llega el 10–15% del tráfico, el tiempo medio de respuesta del sistema completo sigue siendo bajísimo.
La pregunta razonable aquí es: ¿de verdad un modelo tan pequeño es suficiente? La respuesta honesta: para el dominio concreto de una aplicación empresarial — clasificar intenciones, extraer entidades, normalizar variables — sí. Los modelos de 1–3B parámetros de 2026 tienen capacidades que hace dos años requerían modelos de 7B. La brecha se sigue cerrando.
Un único servicio, muchos dominios
Una decisión de diseño que merece la pena explicar: el servicio no sabe nada del dominio en el que opera.
Suena raro al principio. Si el sistema no sabe que está clasificando intenciones médicas, ¿cómo puede clasificarlas bien? La respuesta es que el conocimiento del dominio no vive en el servicio; vive en la petición. Cuando un proyecto invoca el pipeline, le pasa su catálogo de intenciones, sus descripciones, sus ejemplos few-shot y sus pistas de desambiguación. El servicio aplica sus tres capas con esos parámetros y devuelve el resultado.
Esta separación tiene una consecuencia en el día a día: un único microservicio de procesamiento de lenguaje atiende, a la vez, a un IVR sanitario, a un asistente de seguros y a una línea de atención ciudadana. Cada uno con su dominio. Ninguno con código propio. Cuando mejoramos el servicio — añadimos un handler nuevo, afinamos el umbral del fuzzy, actualizamos el modelo — mejoran todos a la vez.
Es el mismo principio de separación de responsabilidades que aplicamos en nuestra arquitectura de agentes de IA serverless, trasladado al mundo del NLP.
La razón menos técnica de todas, y la que más nos importa
Todo lo anterior se puede justificar en una hoja de cálculo: latencia, coste, throughput. Pero hay una razón para apostar por NLP híbrido en local que no aparece en los benchmarks y que, en muchos de nuestros proyectos, es la definitiva: los datos personales del usuario no salen de la infraestructura del cliente.
Esto no es un eslogan. Es una consecuencia arquitectónica. Cuando el pipeline corre entero en la infraestructura del cliente, no hay llamadas salientes, no hay logs remotos, no hay cadena de subprocesadores que auditar. El RGPD, en sectores como sanidad o banca, deja de ser un ejercicio de malabarismo legal para convertirse en algo que se cumple por diseño. Esto conecta directamente con lo que defendemos en nuestro artículo sobre soberanía digital e IA Open Source en Europa: la infraestructura del cliente procesa los datos del cliente.
Cierre: lo que hemos aprendido construyendo este sistema
Si tuviéramos que resumir en tres frases lo que sabemos hoy sobre procesar lenguaje natural en entornos empresariales, serían estas:
- Usa la herramienta que corresponde al problema. Ni más potente, ni menos.
- El LLM debería ser el último recurso, no el primero. Cuando lo reservas para lo que de verdad necesita razonamiento, descubres que puede ser muy pequeño y seguir funcionando.
- La infraestructura local deja de ser una imposición regulatoria y se convierte en una ventaja competitiva en el momento en que tu arquitectura está pensada para vivir en ella.
El NLP híbrido en local no es un parche ni un compromiso. Es, en 2026, la forma madura y sensata de construir sistemas conversacionales que funcionen a escala, respeten la privacidad y no dependan del humor de un proveedor al otro lado del Atlántico.
En Faktoria y en Irontec llevamos tiempo construyendo y desplegando sistemas con esta filosofía en producción. Si quieres ver cómo se aplicaría a tu caso, hablemos.



{kind=link}
{kind=link}
{kind=link}